UMA में मेमोरी में उपयोग की जाने वाली बैंडविड्थ प्रतिबंधित है क्योंकि यह सिंगल मेमोरी कंट्रोलर का उपयोग करती है। NUMA मशीनों के आगमन का मुख्य उद्देश्य कई मेमोरी कंट्रोलरों का उपयोग करके मेमोरी में उपलब्ध बैंडविड्थ को बढ़ाना है।
तुलना चार्ट
| तुलना के लिए आधार | UMA | NUMA |
|---|---|---|
| बुनियादी | एकल मेमोरी नियंत्रक का उपयोग करता है | मल्टीपल मेमोरी कंट्रोलर |
| प्रयुक्त बसों का प्रकार | सिंगल, मल्टीपल और क्रॉसबार। | पेड़ और श्रेणीबद्ध |
| मेमोरी एक्सेस करने का समय | बराबरी का | माइक्रोप्रोसेसर की दूरी के अनुसार परिवर्तन। |
| के लिए उपयुक्त | सामान्य उद्देश्य और समय-साझाकरण अनुप्रयोग | वास्तविक समय और समय-महत्वपूर्ण अनुप्रयोग |
| गति | और धीमा | और तेज |
| बैंडविड्थ | सीमित | UMA से ज्यादा। |
यूएमए की परिभाषा
UMA (यूनिफ़ॉर्म मेमोरी एक्सेस) सिस्टम मल्टीप्रोसेसर के लिए एक साझा मेमोरी आर्किटेक्चर है। इस मॉडल में, एकल मेमोरी का उपयोग किया जाता है और सभी प्रोसेसर द्वारा एक्सेस किया जाता है, जो इंटरकनेक्शन नेटवर्क की मदद से मल्टीप्रोसेसर सिस्टम को प्रस्तुत करता है। प्रत्येक प्रोसेसर में समान मेमोरी एक्सेसिंग टाइम (विलंबता) और एक्सेस स्पीड होती है। यह सिंगल बस, मल्टीपल बस या क्रॉसबार स्विच में से किसी में भी काम कर सकता है। चूंकि यह संतुलित साझा मेमोरी एक्सेस प्रदान करता है, इसलिए इसे एसएमपी (सिमेट्रिक मल्टीप्रोसेसर) सिस्टम के रूप में भी जाना जाता है।
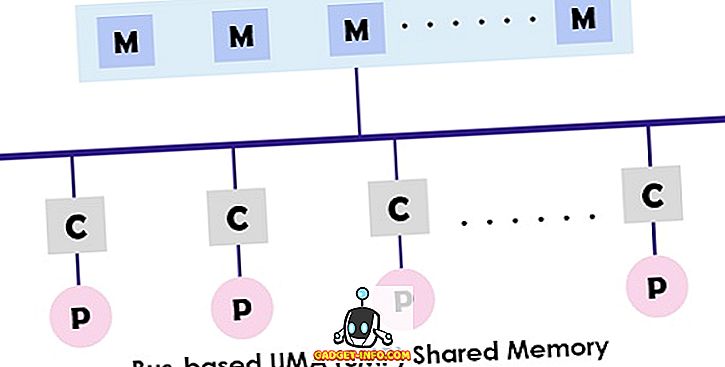
SMP का विशिष्ट डिज़ाइन ऊपर दिखाया गया है जहाँ प्रत्येक प्रोसेसर पहले कैश से जुड़ा होता है फिर कैश बस से जुड़ा होता है। अंत में बस मेमोरी से जुड़ा है। यह यूएमए वास्तुकला व्यक्तिगत पृथक कैश से सीधे निर्देशों को लाने के माध्यम से बस के लिए विवाद को कम करता है। यह प्रत्येक प्रोसेसर को पढ़ने और लिखने के लिए एक समान संभावना भी प्रदान करता है। यूएमए मॉडल के विशिष्ट उदाहरण सन स्टारफायर सर्वर, कॉम्पैक अल्फा सर्वर और एचपी वी श्रृंखला हैं।
NUMA की परिभाषा
NUMA (नॉन-यूनिफ़ॉर्म मेमोरी एक्सेस) भी एक मल्टीप्रोसेसर मॉडल है जिसमें प्रत्येक प्रोसेसर समर्पित मेमोरी से जुड़ा होता है। हालाँकि, मेमोरी के ये छोटे हिस्से एक सिंगल एड्रेस स्पेस बनाने के लिए संयोजित होते हैं। यहां विचार करने का मुख्य बिंदु यह है कि UMA के विपरीत, मेमोरी का एक्सेस समय उस दूरी पर निर्भर करता है जहां प्रोसेसर रखा गया है, जिसका अर्थ है मेमोरी एक्सेस समय अलग-अलग होना। यह भौतिक पते का उपयोग करके किसी भी स्मृति स्थान तक पहुंचने की अनुमति देता है।
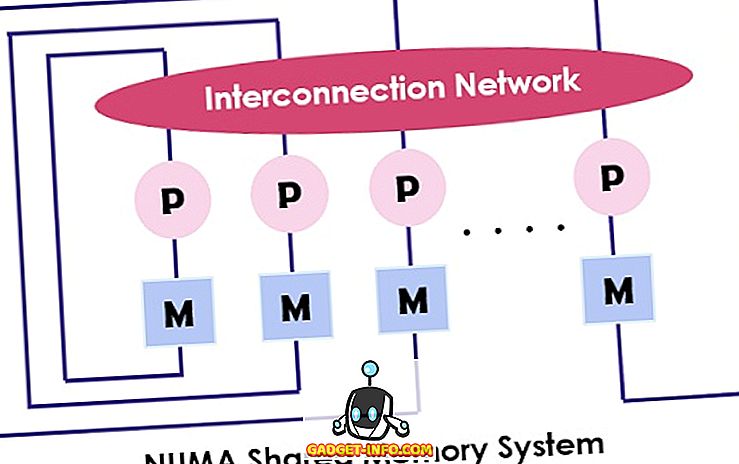
जैसा कि NUMA आर्किटेक्चर के ऊपर उल्लेख किया गया है कि यह मेमोरी के लिए उपलब्ध बैंडविड्थ को बढ़ाने के लिए है और इसके लिए यह कई मेमोरी कंट्रोलर्स का उपयोग करता है। यह कई मशीन कोर को " नोड्स " में जोड़ती है जहां प्रत्येक कोर में एक मेमोरी कंट्रोलर होता है। NUMA मशीन में स्थानीय मेमोरी को एक्सेस करने के लिए कोर अपने नोड द्वारा मेमोरी कंट्रोलर द्वारा प्रबंधित मेमोरी को पुनः प्राप्त करता है। रिमोट मेमोरी को एक्सेस करने के लिए जो अन्य मेमोरी कंट्रोलर द्वारा नियंत्रित की जाती है, कोर इंटरकनेक्शन लिंक के माध्यम से मेमोरी रिक्वेस्ट भेजता है।
NUMA आर्किटेक्चर ट्री और पदानुक्रमित बस नेटवर्क का उपयोग मेमोरी ब्लॉक और प्रोसेसरों को जोड़ने के लिए करता है। BBN, TC-2000, SGI उत्पत्ति 3000, क्रे NUMA वास्तुकला के कुछ उदाहरण हैं।
UMA और NUMA के बीच मुख्य अंतर
- UMA (साझा मेमोरी) मॉडल एक या दो मेमोरी कंट्रोलर्स का उपयोग करता है। जैसा कि है, NUMA में मेमोरी एक्सेस करने के लिए कई मेमोरी कंट्रोलर हो सकते हैं।
- यूएमए आर्किटेक्चर में सिंगल, मल्टीपल और क्रॉसबार बसेस का उपयोग किया जाता है। इसके विपरीत, NUMA पदानुक्रमित और पेड़ के प्रकारों और नेटवर्क कनेक्शन का उपयोग करता है।
- यूएमए में प्रत्येक प्रोसेसर के लिए मेमोरी एक्सेस करने का समय समान होता है जबकि NUMA में मेमोरी एक्सेस करने का समय बदल जाता है क्योंकि प्रोसेसर से मेमोरी की दूरी बदलती है।
- सामान्य उद्देश्य और समय-साझाकरण अनुप्रयोग यूएमए मशीनों के लिए उपयुक्त हैं। इसके विपरीत, एनयूएमए के लिए उपयुक्त आवेदन वास्तविक समय और समय-महत्वपूर्ण केंद्रित है।
- UMA आधारित समानांतर सिस्टम NUMA सिस्टम की तुलना में धीमी गति से काम करता है।
- जब UMA बैंडविड्थ की बात आती है, तो सीमित बैंडविड्थ है। इसके विपरीत, NUMA में UMA से अधिक बैंडविड्थ है।
निष्कर्ष
UMA आर्किटेक्चर मेमोरी को एक्सेस करने वाले प्रोसेसर को एक ही समग्र विलंबता प्रदान करता है। यह बहुत उपयोगी नहीं है जब स्थानीय मेमोरी एक्सेस की जाती है क्योंकि विलंबता एक समान होगी। दूसरी ओर, NUMA में प्रत्येक प्रोसेसर की अपनी समर्पित मेमोरी होती है जो स्थानीय मेमोरी एक्सेस होने पर विलंबता को समाप्त कर देती है। प्रोसेसर और मेमोरी में परिवर्तन (यानी, गैर-समान) के बीच की दूरी के रूप में विलंबता बदल जाती है। हालाँकि, NMA ने UMA आर्किटेक्चर की तुलना में प्रदर्शन में सुधार किया है।