एक्सेल एक बहुमुखी अनुप्रयोग है, जो अपने शुरुआती संस्करणों से कहीं आगे बढ़कर एक स्प्रेडशीट समाधान है। एक रिकॉर्ड कीपर, एड्रेस बुक, फोरकास्टिंग टूल और बहुत कुछ के रूप में कार्यरत, बहुत से लोग एक्सेल का उपयोग उन तरीकों से भी करते हैं जो कभी भी इरादा नहीं था।
यदि आप घर या कार्यालय में एक्सेल का उपयोग करते हैं, तो आप जानते हैं कि कभी-कभी आपके द्वारा काम किए जाने वाले रिकॉर्ड की संख्या के कारण एक्सेल फाइलें जल्दी से बेकार हो सकती हैं।
सौभाग्य से, एक्सेल में डुप्लिकेट रिकॉर्ड खोजने और निकालने में आपकी सहायता के लिए अंतर्निहित कार्य हैं। दुर्भाग्य से, इन कार्यों का उपयोग करने के लिए कुछ चेतावनी हैं, इसलिए सावधान रहें या आप अनजाने में उन रिकॉर्ड को हटा सकते हैं जिन्हें आपने हटाने का इरादा नहीं किया था। इसके अलावा, नीचे दिए गए दोनों तरीके बिना डुप्लिकेट को हटाए बिना आपको बता देते हैं कि क्या हटाया गया था।
मैं उन पंक्तियों को हाइलाइट करने का एक तरीका भी बताऊंगा जो पहले डुप्लिकेट हैं, ताकि आप देख सकें कि कौन से फ़ंक्शंस आपको चलाने से पहले हटा दिए जाएंगे। पूरी तरह से डुप्लिकेट पंक्ति को हाइलाइट करने के लिए आपको कस्टम सशर्त स्वरूपण नियम का उपयोग करना होगा।
डुप्लिकेट फ़ंक्शन निकालें
मान लीजिए कि आप पतों का ट्रैक रखने के लिए एक्सेल का उपयोग करते हैं और आपको संदेह है कि आपके पास डुप्लिकेट रिकॉर्ड हैं। नीचे दिए गए एक्सेल वर्कशीट के उदाहरण को देखें:
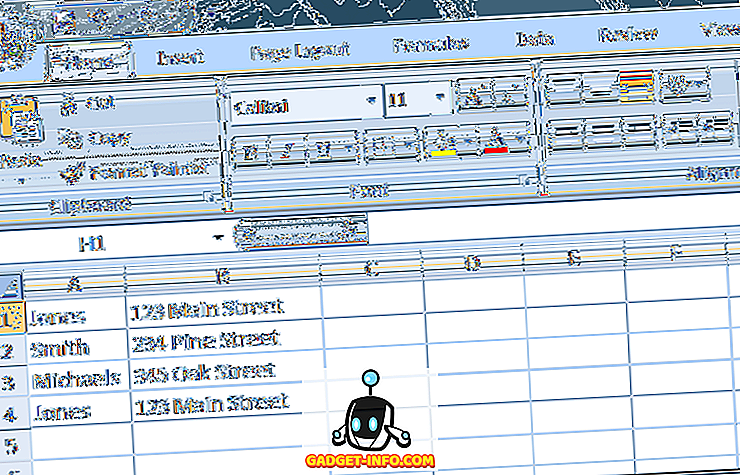
ध्यान दें कि "जोन्स" रिकॉर्ड दो बार दिखाई देता है। ऐसे डुप्लिकेट रिकॉर्ड को निकालने के लिए, रिबन पर डेटा टैब पर क्लिक करें और डेटा उपकरण अनुभाग के तहत डुप्लिकेट निकालें फ़ंक्शन का पता लगाएं। निकालें डुप्लिकेट पर क्लिक करें और एक नई विंडो खुलती है।

यहां आपको यह निर्णय लेना होगा कि आप अपने कॉलम के शीर्ष पर हेडिंग लेबल का उपयोग करते हैं या नहीं। यदि आप करते हैं, तो मेरा डेटा हैड हेडर्स लेबल वाला विकल्प चुनें। यदि आप हेडिंग लेबल का उपयोग नहीं करते हैं, तो आप एक्सेल के मानक कॉलम पदनामों का उपयोग करेंगे, जैसे कि कॉलम ए, कॉलम बी, आदि।
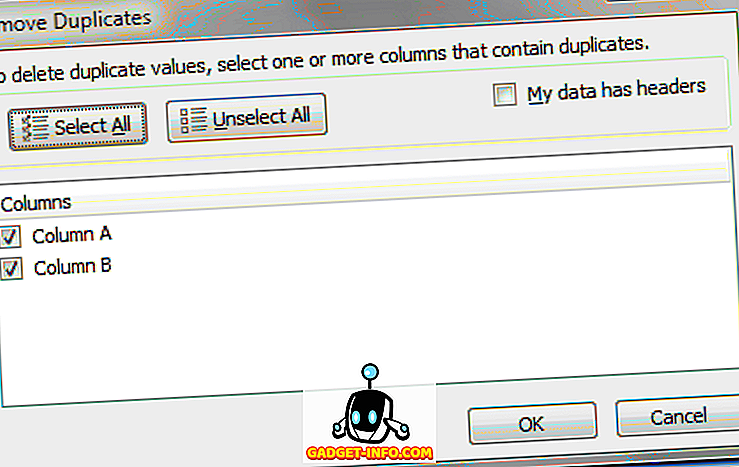
इस उदाहरण के लिए, हम केवल कॉलम A चुनेंगे और OK बटन पर क्लिक करेंगे। विकल्प विंडो बंद हो जाती है और Excel दूसरा "जोन्स" रिकॉर्ड निकालता है।
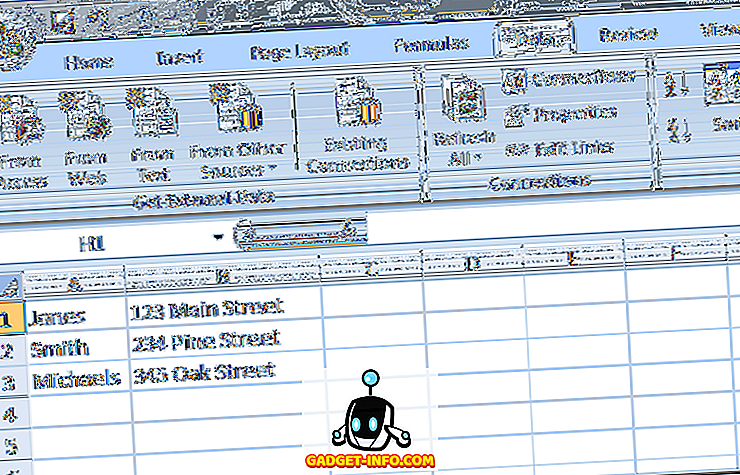
बेशक, यह सिर्फ एक सरल उदाहरण था। एक्सेल का उपयोग करके आप जो भी पता रिकॉर्ड करते हैं, वह बहुत अधिक जटिल होने की संभावना है। मान लीजिए, उदाहरण के लिए, आपके पास एक पता फ़ाइल है जो इस तरह दिखती है।
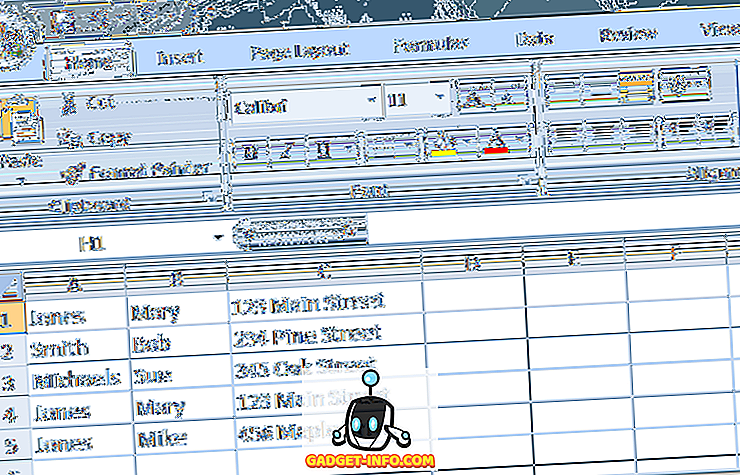
ध्यान दें कि हालांकि तीन "जोन्स" रिकॉर्ड हैं, केवल दो समान हैं। यदि हम डुप्लिकेट रिकॉर्ड को हटाने के लिए ऊपर की प्रक्रियाओं का उपयोग करते हैं, तो केवल एक "जोन्स" प्रविष्टि बनी रहेगी। इस मामले में, हमें अपने निर्णय मानदंडों को क्रमशः कॉलम ए और बी में पाए जाने वाले पहले और अंतिम दोनों नामों को शामिल करने की आवश्यकता है।
ऐसा करने के लिए, एक बार फिर रिबन पर डेटा टैब पर क्लिक करें और फिर निकालें डुप्लिकेट पर क्लिक करें। इस बार, जब विकल्प विंडो पॉप अप हो जाती है, तो कॉलम ए और बी चुनें ठीक बटन पर क्लिक करें और ध्यान दें कि इस बार एक्सेल ने "मैरी जोन्स" रिकॉर्ड में से केवल एक को हटा दिया।
ऐसा इसलिए है क्योंकि हमने एक्सेल को केवल कॉलम ए के बजाय कॉलम ए और बी पर आधारित रिकॉर्ड्स से मेल खाते हुए डुप्लिकेट को हटाने के लिए कहा था। आपके द्वारा चुने गए अधिक कॉलम, एक्सेल से पहले एक रिकॉर्ड को डुप्लिकेट मानने के लिए अधिक मानदंडों को पूरा करना होगा। यदि आप पूरी तरह से डुप्लिकेट हैं पंक्तियों को निकालना चाहते हैं, तो सभी कॉलम चुनें।
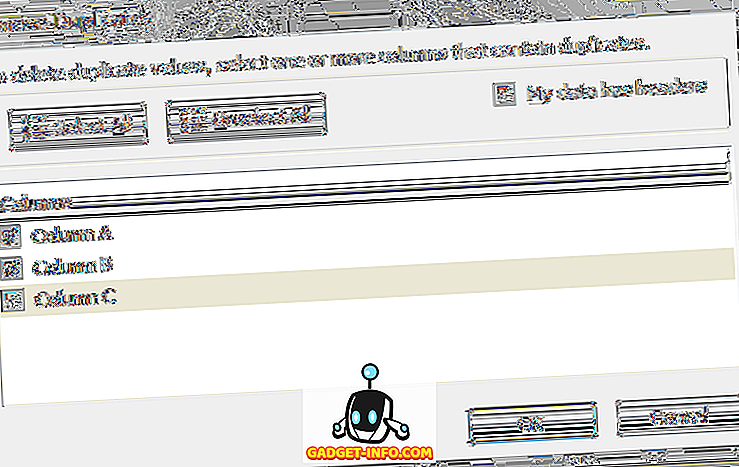
एक्सेल आपको एक संदेश देगा जिसमें बताया गया था कि कितने डुप्लिकेट निकाले गए थे। हालाँकि, यह नहीं दिखाया जाएगा कि कौन सी पंक्तियाँ हटा दी गईं! इस फ़ंक्शन को चलाने से पहले डुप्लिकेट पंक्तियों को हाइलाइट करने के तरीके को देखने के लिए अंतिम अनुभाग तक स्क्रॉल करें।

उन्नत फ़िल्टर विधि
डुप्लिकेट को निकालने का दूसरा तरीका उन्नत फ़िल्टर विकल्प का उपयोग करना है। सबसे पहले, शीट में सभी डेटा का चयन करें। अगला, रिबन में डेटा टैब पर, सॉर्ट और फ़िल्टर अनुभाग में उन्नत पर क्लिक करें ।
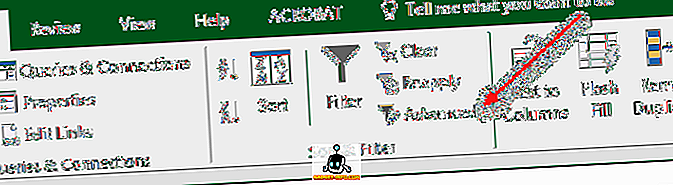
पॉप अप होने वाले संवाद में, केवल अनन्य रिकॉर्ड चेकबॉक्स चेक करना सुनिश्चित करें।
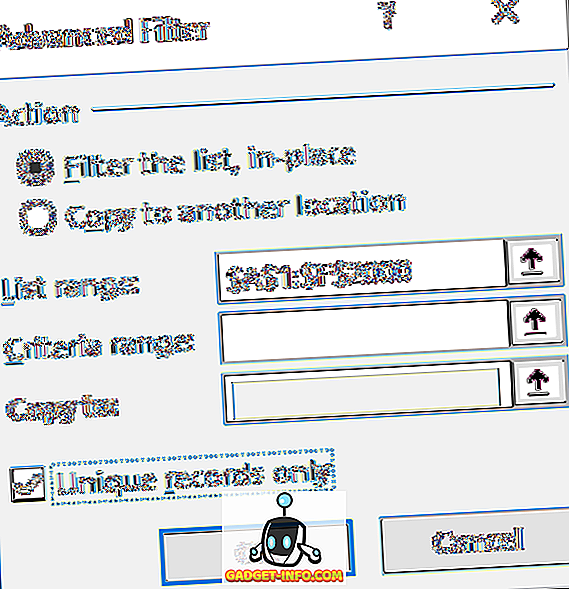
आप या तो सूची को जगह में फ़िल्टर कर सकते हैं या आप गैर-डुप्लिकेट आइटम को उसी स्प्रेडशीट के दूसरे भाग में कॉपी कर सकते हैं। किसी विषम कारण के लिए, आप डेटा को दूसरी शीट पर कॉपी नहीं कर सकते। यदि आप इसे किसी अन्य शीट पर चाहते हैं, तो पहले वर्तमान शीट पर एक स्थान चुनें और फिर उस डेटा को एक नई शीट में काटें और पेस्ट करें।
इस पद्धति के साथ, आपको यह बताने का संदेश भी नहीं मिलता है कि कितनी पंक्तियों को हटा दिया गया था। पंक्तियों को हटा दिया जाता है और यह बात है।
एक्सेल में डुप्लिकेट पंक्तियों को हाइलाइट करें
यदि आप देखना चाहते हैं कि उन्हें हटाने से पहले कौन से रिकॉर्ड डुप्लिकेट हैं, तो आपको थोड़ा मैनुअल काम करना होगा। दुर्भाग्य से, एक्सेल में पंक्तियों को उजागर करने का एक तरीका नहीं है जो पूरी तरह से डुप्लिकेट हैं। इसमें सशर्त स्वरूपण के तहत एक विशेषता है जो डुप्लिकेट कोशिकाओं को उजागर करता है, लेकिन यह लेख डुप्लिकेट पंक्तियों के बारे में है।
पहली चीज जो आपको करने की आवश्यकता है वह है कॉलम में अपने डेटा के सेट के दाईं ओर एक सूत्र जोड़ना। सूत्र सरल है: बस उस पंक्ति के सभी स्तंभों को एक साथ सम्मिलित करें।
= ए 1 और बी 1 और सी 1 और डी 1 और ई 1
नीचे मेरे उदाहरण में, मेरे पास कॉलम ए थ्रू एफ में डेटा है। हालांकि, पहला कॉलम एक आईडी नंबर है, इसलिए मैं नीचे दिए गए अपने सूत्र से इसे बाहर करता हूं। उन सभी स्तंभों को शामिल करना सुनिश्चित करें जिनके पास डेटा है जिन्हें आप डुप्लिकेट के लिए जांचना चाहते हैं।

मैंने उस सूत्र को स्तंभ H में रखा और फिर उसे अपनी सभी पंक्तियों के लिए नीचे खींच लिया। यह फॉर्मूला प्रत्येक कॉलम के सभी डेटा को केवल एक बड़े टेक्स्ट के टुकड़े के रूप में जोड़ता है। अब, कुछ और कॉलमों को छोड़ें और निम्न सूत्र दर्ज करें:
= COUNTIF ($ H $ 1: $ H $ 34, $ H1)> 1
यहां हम COUNTIF फ़ंक्शन का उपयोग कर रहे हैं और पहला पैरामीटर उस डेटा का सेट है जिसे हम देखना चाहते हैं। मेरे लिए, यह पंक्ति 1 से 34 तक कॉलम H (जिसमें कंबाइन डेटा फॉर्मूला है) है। ऐसा करने से पहले हेडर पंक्ति से छुटकारा पाना भी एक अच्छा विचार है।
आप यह भी सुनिश्चित करना चाहेंगे कि आप अक्षर और संख्या के सामने डॉलर चिह्न ($) का उपयोग करें। यदि आपके पास 1000 पंक्तियों का डेटा है और आपका संयुक्त पंक्ति सूत्र स्तंभ F में है, उदाहरण के लिए, आपका सूत्र इसके बजाय ऐसा दिखेगा:
= COUNTIF ($ F $ 1: $ F $ 1000, $ F1)> 1
दूसरे पैरामीटर में कॉलम अक्षर के सामने केवल डॉलर का चिह्न होता है ताकि लॉक हो, लेकिन हम पंक्ति संख्या को लॉक नहीं करना चाहते हैं। फिर, आप अपने सभी डेटा की पंक्तियों के लिए इसे नीचे खींच लेंगे। यह इस तरह दिखना चाहिए और डुप्लिकेट पंक्तियों में TRUE होना चाहिए।
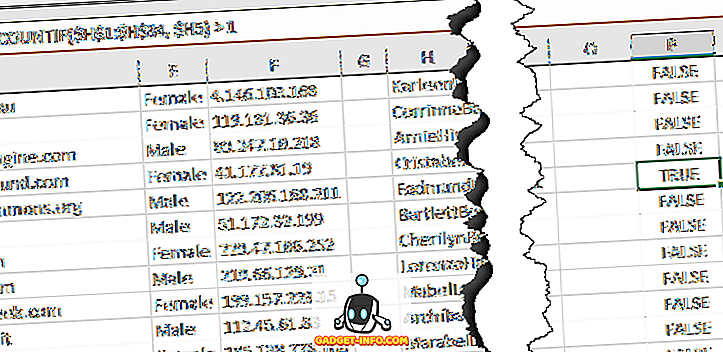
अब, उन पंक्तियों को हाइलाइट करें जिनमें TRUE है क्योंकि वे डुप्लिकेट पंक्तियाँ हैं। सबसे पहले, पंक्तियों और स्तंभों के शीर्ष बाएँ चौराहे पर थोड़ा त्रिकोण पर क्लिक करके डेटा की पूरी वर्कशीट का चयन करें। अब होम टैब पर जाएं, फिर कंडिशनल फॉर्मेटिंग पर क्लिक करें और न्यू रूल पर क्लिक करें।
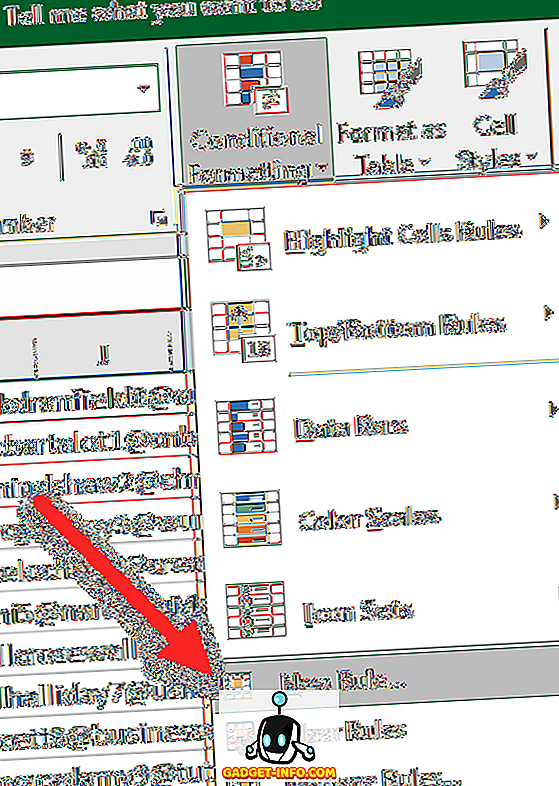
संवाद में, कौन से कक्षों को स्वरूपित करना है यह निर्धारित करने के लिए सूत्र का उपयोग करें पर क्लिक करें ।
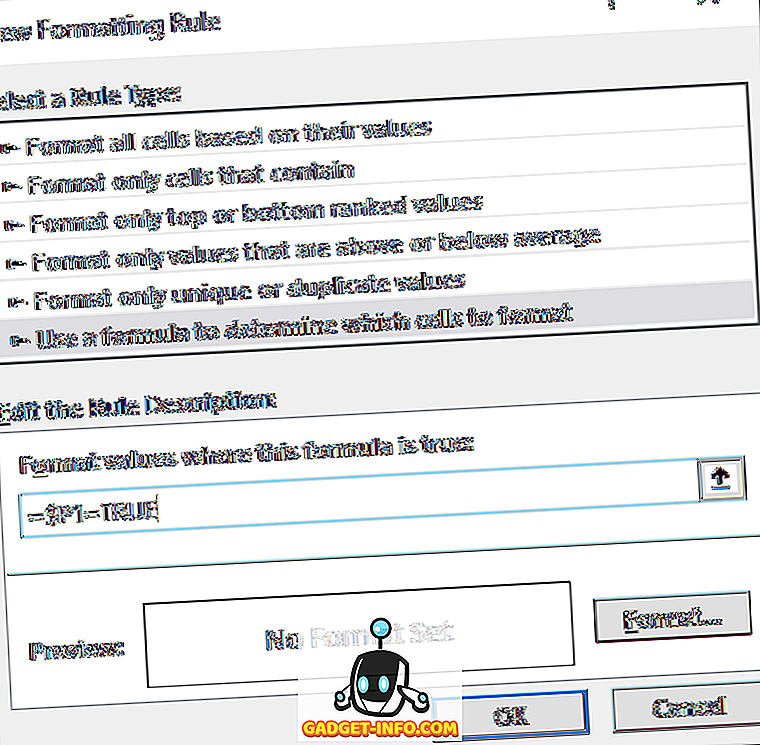
जहाँ यह सूत्र सत्य है, स्वरूप मान के अंतर्गत बॉक्स में : निम्न सूत्र दर्ज करें, जिसमें P आपके स्तंभ के साथ TRUE या FALSE मान है। कॉलम पत्र के सामने डॉलर का चिह्न शामिल करना सुनिश्चित करें।
= $ पी 1 = TRUE
एक बार जब आप ऐसा कर लेते हैं, तो प्रारूप पर क्लिक करें और भरें टैब पर क्लिक करें। एक रंग चुनें और जिसका उपयोग संपूर्ण डुप्लिकेट पंक्ति को हाइलाइट करने के लिए किया जाएगा। ठीक पर क्लिक करें और आपको अब देखना चाहिए कि डुप्लिकेट पंक्तियाँ हाइलाइट की गई हैं।
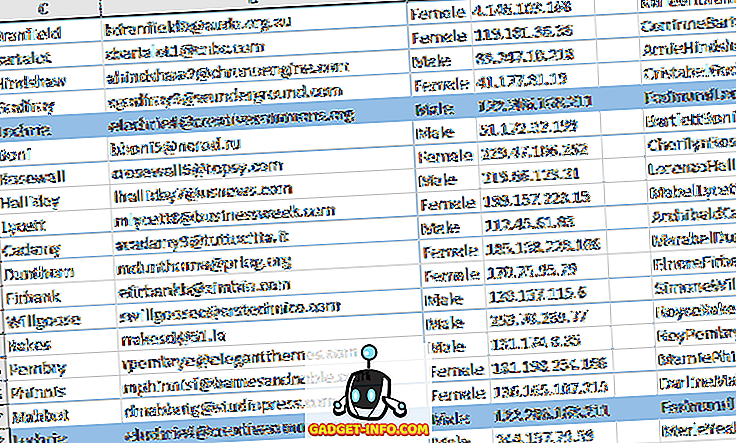
यदि यह आपके लिए काम नहीं करता है, तो शुरू करें और इसे फिर से धीरे-धीरे करें। यह सब काम करने के लिए बिल्कुल ठीक किया जाना चाहिए। यदि आप रास्ते में एक भी $ चिन्ह याद करते हैं, तो यह ठीक से काम नहीं करेगा।
डुप्लिकेट रिकॉर्ड्स को हटाने के साथ कैविट्स
बेशक, एक्सेल को स्वचालित रूप से आपके लिए डुप्लिकेट रिकॉर्ड को हटाने देने में कुछ समस्याएं हैं। सबसे पहले, आपको डुप्लिकेट रिकॉर्ड की पहचान करने के लिए मानदंड के रूप में उपयोग करने के लिए एक्सेल के लिए बहुत कम या बहुत अधिक कॉलम चुनने से सावधान रहना होगा।
बहुत कम और आप अनजाने में अपने रिकॉर्ड को हटा सकते हैं। बहुत से या गलती से एक पहचानकर्ता कॉलम सहित और कोई डुप्लिकेट नहीं मिलेगा।
दूसरा, एक्सेल हमेशा मानता है कि यह पहला अनूठा रिकॉर्ड है जो मास्टर रिकॉर्ड है। किसी भी बाद के रिकॉर्ड को डुप्लिकेट माना जाता है। यह एक समस्या है अगर, उदाहरण के लिए, आप अपनी फ़ाइल में किसी एक व्यक्ति के पते में संशोधन करने में विफल रहे, बल्कि एक नया रिकॉर्ड बनाया।
यदि नया (सही) पता रिकॉर्ड पुराने (आउट-ऑफ-डेट) रिकॉर्ड के बाद दिखाई देता है, तो एक्सेल मान लेगा कि मास्टर होने के लिए पहला (आउट-ऑफ-डेट) रिकॉर्ड है और बाद में मिलने वाले किसी भी रिकॉर्ड को हटा दें। यही कारण है कि आपको सावधान रहना होगा कि एक्सेल को उदारतापूर्वक या रूढ़िवादी तरीके से आप कैसे तय करते हैं कि डुप्लिकेट रिकॉर्ड क्या है या नहीं।
उन मामलों के लिए, आपको मेरे द्वारा लिखे गए हाइलाइट डुप्लिकेट विधि का उपयोग करना चाहिए और मैन्युअल रूप से उपयुक्त डुप्लिकेट रिकॉर्ड को हटाना चाहिए।
अंत में, एक्सेल आपको यह सत्यापित करने के लिए नहीं कहता है कि क्या आप वास्तव में एक रिकॉर्ड हटाना चाहते हैं। आपके द्वारा चुने गए (कॉलम) मापदंडों का उपयोग करते हुए, प्रक्रिया पूरी तरह से स्वचालित है। यह एक खतरनाक बात हो सकती है जब आपके पास भारी संख्या में रिकॉर्ड हों और आपको भरोसा हो कि आपके द्वारा लिए गए निर्णय सही थे और एक्सेल आपके लिए डुप्लिकेट रिकॉर्ड को स्वचालित रूप से हटाने की अनुमति देता है।
इसके अलावा, एक्सेल में खाली लाइनों को हटाने पर हमारे पिछले लेख को देखना सुनिश्चित करें। का आनंद लें!