एक्सेल स्प्रेडशीट में डेटा प्रविष्टि को सरल और / या मानकीकृत करने के लिए अक्सर सेल ड्रॉपडाउन शामिल होते हैं। स्वीकार्य प्रविष्टियों की सूची निर्दिष्ट करने के लिए डेटा सत्यापन सुविधा का उपयोग करके ये ड्रॉपडाउन बनाए जाते हैं।
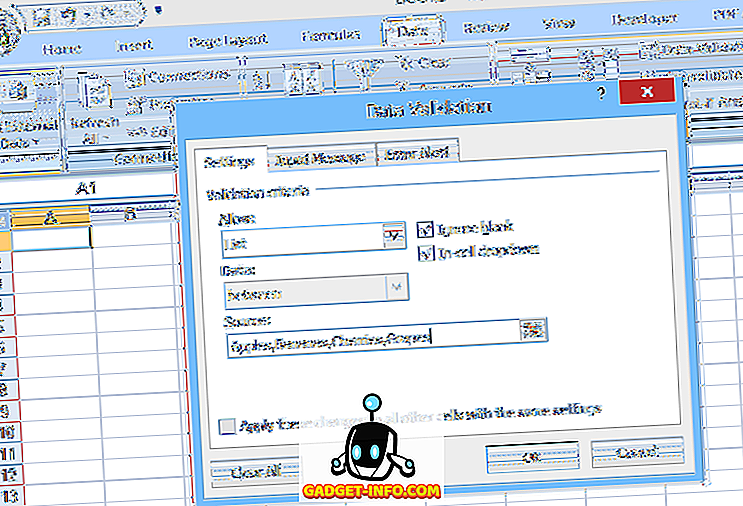
एक सरल ड्रॉपडाउन सूची सेट करने के लिए, उस सेल का चयन करें जहां डेटा दर्ज किया जाएगा, फिर डेटा सत्यापन पर क्लिक करें ( डेटा टैब पर), डेटा सत्यापन चुनें, सूची चुनें (अनुमति दें :) के तहत, और फिर सूची आइटम दर्ज करें (अल्पविराम द्वारा अलग) ) स्रोत में : फ़ील्ड (चित्र 1 देखें)।
इस प्रकार की मूल गिरावट में, डेटा सत्यापन के भीतर ही स्वीकार्य प्रविष्टियों की सूची निर्दिष्ट की जाती है; इसलिए, सूची में परिवर्तन करने के लिए, उपयोगकर्ता को डेटा सत्यापन खोलना और संपादित करना होगा। हालांकि, अनुभवहीन उपयोगकर्ताओं के लिए या ऐसे मामलों में मुश्किल हो सकती है, जहां विकल्पों की सूची लंबी है।
एक अन्य विकल्प है कि सूची को स्प्रैडशीट के भीतर एक नामित सीमा में रखा जाए, और फिर उस श्रेणी नाम (समान चिह्न के साथ पूर्वनिर्धारित) को स्रोत में निर्दिष्ट करें: डेटा सत्यापन का क्षेत्र (जैसा कि चित्र 2 में दिखाया गया है)।
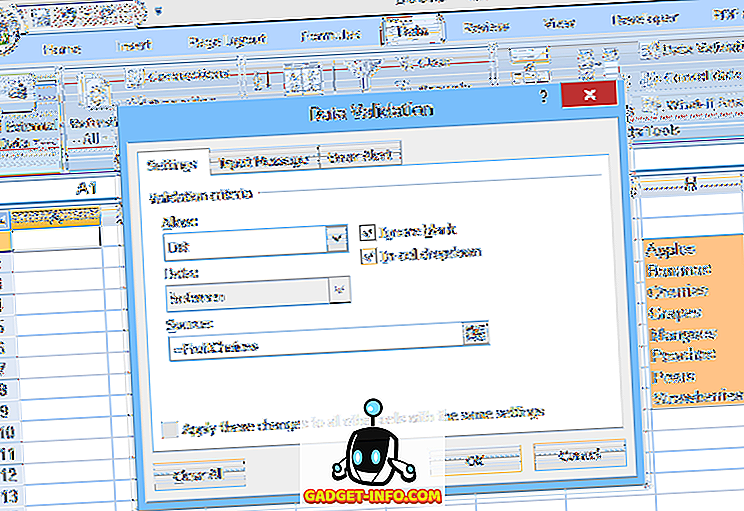
यह दूसरी विधि सूची में विकल्पों को संपादित करना आसान बनाती है, लेकिन आइटम जोड़ना या निकालना समस्याग्रस्त हो सकता है। चूंकि नामित सीमा (फ्रूटचॉइज, हमारे उदाहरण में) कोशिकाओं की एक निश्चित सीमा को संदर्भित करता है ($ H $ 3: $ H $ 10 जैसा कि दिखाया गया है), यदि अधिक विकल्प H11 या उससे नीचे की कोशिकाओं में जोड़े जाते हैं, तो वे ड्रॉपडाउन में दिखाई नहीं देंगे। (चूँकि वे कोशिकाएँ फ्रूटचाइज़ रेंज का हिस्सा नहीं हैं)।
इसी तरह, यदि, उदाहरण के लिए, नाशपाती और स्ट्रॉबेरी प्रविष्टियां मिट जाती हैं, तो वे अब ड्रॉपडाउन में दिखाई नहीं देंगे, लेकिन इसके बजाय ड्रॉपडाउन में दो "खाली" विकल्प शामिल होंगे क्योंकि ड्रॉपडाउन अभी भी पूरे FruitChoices रेंज को संदर्भित करता है, जिसमें खाली सेल H9 और एच 10।
इन कारणों से, जब ड्रॉपडाउन के लिए सूची स्रोत के रूप में एक सामान्य नामित सीमा का उपयोग किया जाता है, तो नामांकित सीमा को अधिक या कम कोशिकाओं को शामिल करने के लिए संपादित किया जाना चाहिए यदि प्रविष्टियों को सूची से जोड़ा जाता है या हटा दिया जाता है।
इस समस्या का एक समाधान ड्रॉपडाउन विकल्पों के स्रोत के रूप में एक गतिशील रेंज नाम का उपयोग करना है। डायनामिक रेंज नाम वह है जो स्वचालित रूप से डेटा के ब्लॉक के आकार से मेल खाने या हटाने के लिए फैलता है (या अनुबंध)। ऐसा करने के लिए, आप नामांकित श्रेणी को परिभाषित करने के लिए, सेल पतों की एक निश्चित सीमा के बजाय एक सूत्र का उपयोग करते हैं।
एक्सेल में डायनामिक रेंज कैसे सेटअप करें
एक सामान्य (स्थैतिक) श्रेणी नाम कोशिकाओं की एक निर्दिष्ट श्रेणी को संदर्भित करता है ($ H $ 3: $ H $ 10 हमारे उदाहरण में, नीचे देखें):
लेकिन एक डायनामिक रेंज को एक सूत्र का उपयोग करके परिभाषित किया गया है (नीचे देखें, एक अलग स्प्रेडशीट से लिया गया है जो डायनामिक रेंज नामों का उपयोग करता है):
इससे पहले कि हम शुरू करें, सुनिश्चित करें कि आप हमारी एक्सेल उदाहरण फ़ाइल डाउनलोड करें (सॉर्ट मैक्रो को अक्षम कर दिया गया है)।
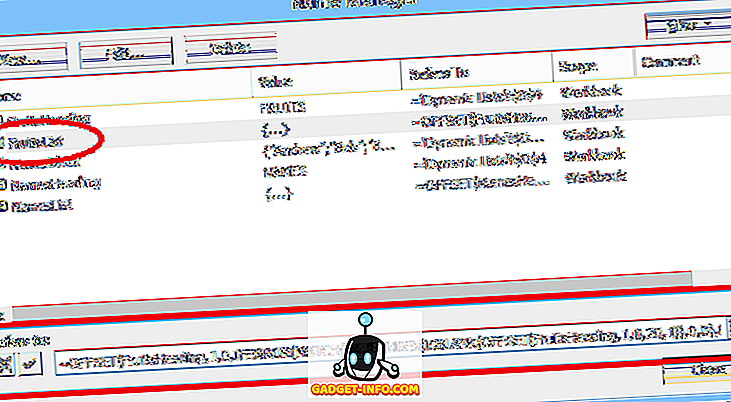
आइए इस सूत्र की विस्तार से जांच करें। फलों के लिए विकल्प सीधे एक शीर्षक ( FRUITS ) के नीचे कोशिकाओं के एक ब्लॉक में हैं। उस शीर्षक को एक नाम भी दिया गया है: FruitHeading :
फलों के विकल्पों के लिए डायनामिक रेंज को परिभाषित करने के लिए उपयोग किया जाने वाला संपूर्ण सूत्र है:
= OFFSET (FruitsHeading, 1, 0, IFERROR (मैच (TRUE, सूचकांक (ISBLANK (FruitsHeading ऑफसेट (, 1, 0, 20, 1)), 0, 0), 0) -1, 20), 1)
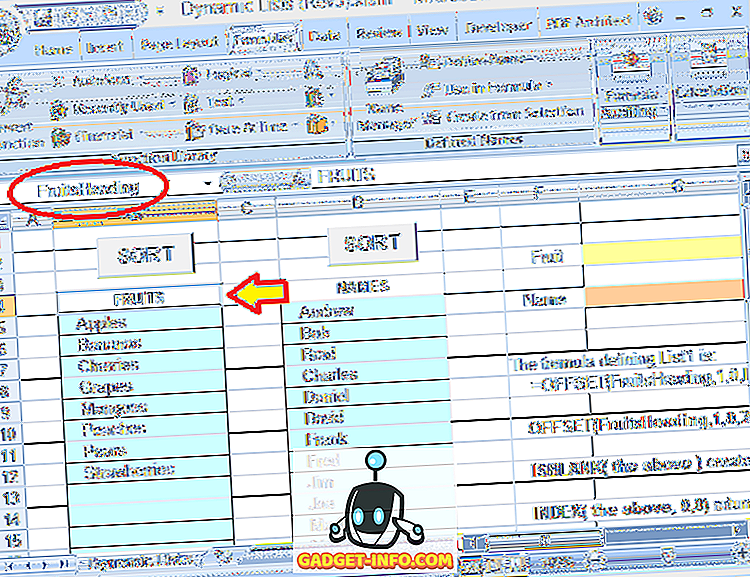
फ्रूटहेडिंग से तात्पर्य उस शीर्षक से है जो सूची में पहली प्रविष्टि के ऊपर एक पंक्ति है। संख्या 20 (सूत्र में दो बार प्रयुक्त) सूची के लिए अधिकतम आकार (पंक्तियों की संख्या) है (इसे वांछित के रूप में समायोजित किया जा सकता है)।
ध्यान दें कि इस उदाहरण में, सूची में केवल 8 प्रविष्टियाँ हैं, लेकिन इनके नीचे खाली कक्ष भी हैं जहाँ अतिरिक्त प्रविष्टियाँ जोड़ी जा सकती हैं। संख्या 20 पूरे ब्लॉक को संदर्भित करती है जहां प्रविष्टियां बनाई जा सकती हैं, न कि प्रविष्टियों की वास्तविक संख्या के लिए।
अब आइए सूत्र को टुकड़ों में तोड़ते हैं (प्रत्येक टुकड़े को रंग-कोडिंग करते हैं), यह समझने के लिए कि यह कैसे काम करता है:
= OFFSET (फ्रूट हियरिंग, 1, 0, IFERROR (MATCH (TRUE, INDEX) (ISFSANK ( OFFSET, 1, 0, 20, 1) ), 0, 0), 0) -1, 20), 1)
"अंतरतम" टुकड़ा OFFSET (फ्रूटहेडिंग, 1, 0, 20, 1) है । यह 20 कोशिकाओं के ब्लॉक (फ्रूटहेडिंग सेल के नीचे) को संदर्भित करता है, जहां विकल्प दर्ज किए जा सकते हैं। यह OFFSET फ़ंक्शन मूल रूप से कहता है: FruitHeading सेल पर शुरू करें, 1 पंक्ति से नीचे और 0 कॉलम पर जाएं, फिर एक क्षेत्र चुनें जो 20 पंक्तियों लंबा और 1 स्तंभ चौड़ा हो। तो इससे हमें 20-पंक्ति ब्लॉक मिलती है जहां फलों के विकल्प दर्ज किए जाते हैं।
सूत्र का अगला भाग ISBLANK फ़ंक्शन है:
= OFFSET (फ्रूट हियरिंग, 1, 0, IFERROR (MATCH (TRUE, INDEX ( ISBLANK) (ऊपर)), 0, 0), 0) -1, 20), 1)
यहाँ, OFFSET फ़ंक्शन (ऊपर समझाया गया है) को "उपरोक्त" (पढ़ने में आसान बनाने के लिए) के साथ बदल दिया गया है। लेकिन ISBLANK फ़ंक्शन उन कोशिकाओं की 20-पंक्ति श्रेणी पर काम कर रहा है जो OFFSET फ़ंक्शन को परिभाषित करता है।
तब ISBLANK 20 TRUE और FALSE मूल्यों का एक सेट बनाता है, जो दर्शाता है कि OFFSET फ़ंक्शन द्वारा संदर्भित 20-पंक्ति रेंज में प्रत्येक व्यक्तिगत कोशिका रिक्त (खाली) है या नहीं। इस उदाहरण में, सेट में पहले 8 मान FALSE होंगे क्योंकि पहले 8 सेल खाली नहीं हैं और अंतिम 12 मान TRUE होंगे।
सूत्र का अगला भाग INDEX फ़ंक्शन है:
= OFFSET (फ्रूट हियरिंग, 1, 0, IFERROR (MATCH (TRUE, INDEX (उपरोक्त, 0, 0), 0) -1, 20), 1)
फिर, "उपर्युक्त" ऊपर वर्णित ISBLANK और OFFSET फ़ंक्शन को संदर्भित करता है। INDEX फ़ंक्शन एक सरणी देता है जिसमें ISBLANK फ़ंक्शन द्वारा बनाए गए 20 TRUE / FALSE मान होते हैं।
INDEX का उपयोग आम तौर पर एक निश्चित पंक्ति और स्तंभ (उस ब्लॉक के भीतर) को निर्दिष्ट करके, डेटा के ब्लॉक से एक निश्चित मान (या मानों की श्रेणी) लेने के लिए किया जाता है। लेकिन पंक्ति और स्तंभ इनपुट को शून्य पर सेट करना (जैसा कि यहां किया गया है) INDEX को डेटा के पूरे ब्लॉक वाले एक सरणी को वापस करने का कारण बनता है।
सूत्र का अगला टुकड़ा MATCH फ़ंक्शन है:
= OFFSET (फ्रूट हियरिंग, 1, 0, IFERROR ( MATCH (TRUE, उपरोक्त, 0) -1, 20), 1)
MATCH फ़ंक्शन INDEX फ़ंक्शन द्वारा दिए गए सरणी के भीतर, पहले TRUE मान की स्थिति लौटाता है। चूंकि सूची में पहले 8 प्रविष्टियां रिक्त नहीं हैं, सरणी में पहले 8 मान FALSE होंगे, और नौवां मान TRUE होगा (चूंकि सीमा में 9 वीं पंक्ति खाली है)।
तो MATCH फ़ंक्शन 9 का मान लौटाएगा। इस मामले में, हालांकि, हम वास्तव में यह जानना चाहते हैं कि सूची में कितनी प्रविष्टियाँ हैं, इसलिए सूत्र MATCH मान से 1 घटाता है (जो अंतिम प्रविष्टि की स्थिति देता है)। तो अंततः, MATCH (TRUE, उपरोक्त, 0) -1 8 का मान लौटाता है।
सूत्र का अगला भाग IFERROR फ़ंक्शन है:
= OFFSET (फल, फल, 1, 0, IFERROR (ऊपर, 20), 1)
IFERROR फ़ंक्शन एक वैकल्पिक मान लौटाता है, यदि पहला मान किसी त्रुटि में निर्दिष्ट होता है। यह फ़ंक्शन तब से शामिल है, यदि कक्षों का पूरा ब्लॉक (सभी 20 पंक्तियाँ) प्रविष्टियों से भरा हुआ है, तो MATCH फ़ंक्शन एक त्रुटि लौटाएगा।
इसका कारण यह है कि हम MATCH फ़ंक्शन को पहले TRUE मान (ISBLANK फ़ंक्शन से मानों की सरणी में) देखने के लिए कह रहे हैं, लेकिन यदि कक्षों का कोई भी रिक्त नहीं है, तो संपूर्ण सरणी FALSE मानों से भर जाएगी। यदि MATCH लक्ष्य मान (TRUE) को उस सरणी में नहीं खोज पा रहा है जिसे वह खोज रहा है, तो वह एक त्रुटि देता है।
इसलिए, यदि पूरी सूची पूर्ण है (और इसलिए, MATCH एक त्रुटि देता है), IFERROR फ़ंक्शन इसके बजाय 20 का मान लौटाएगा (यह जानकर कि सूची में 20 प्रविष्टियाँ होनी चाहिए)।
अंत में, OFFSET (FruitHeading, 1, 0, इसके बाद के संस्करण, 1) वह सीमा लौटाता है जिसकी हम वास्तव में तलाश कर रहे हैं: FruitHeading सेल पर शुरू करें, 1 पंक्ति और 0 से अधिक स्तंभों पर जाएं, फिर एक ऐसे क्षेत्र का चयन करें जो कि कई पंक्तियों से लंबा हो सूची में प्रविष्टियाँ हैं (और 1 स्तंभ चौड़ा)। तो एक साथ पूरा फॉर्मूला उस सीमा को लौटा देगा जिसमें केवल वास्तविक प्रविष्टियाँ हैं (पहली खाली सेल के नीचे)।
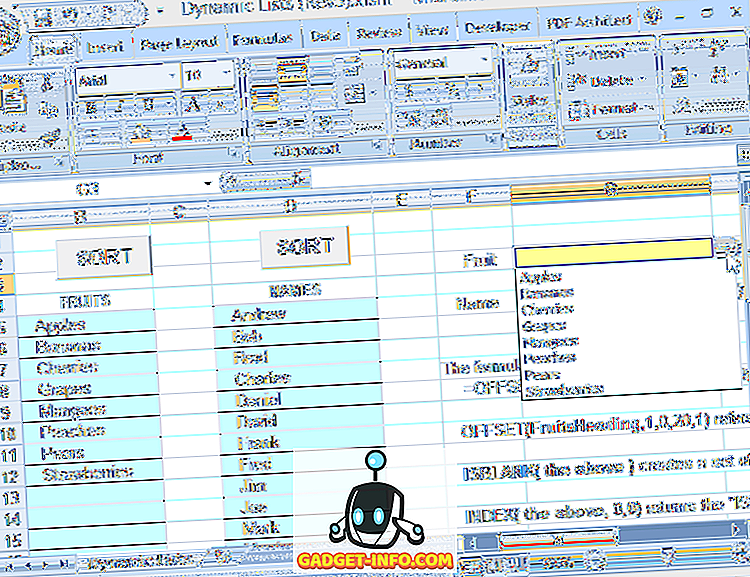
ड्रॉपडाउन के लिए स्रोत की सीमा को परिभाषित करने के लिए इस सूत्र का उपयोग करने का मतलब है कि आप सूची को स्वतंत्र रूप से संपादित कर सकते हैं (प्रविष्टियों को जोड़ना या निकालना, जब तक कि शेष प्रविष्टियां शीर्ष सेल पर शुरू होती हैं और सन्निहित हैं) और ड्रॉपडाउन हमेशा वर्तमान को प्रतिबिंबित करेगा सूची (चित्र 6 देखें)
यहां उपयोग की जाने वाली उदाहरण फ़ाइल (डायनामिक सूची) शामिल है और इस वेबसाइट से डाउनलोड करने योग्य है। हालाँकि, मैक्रोज़ काम नहीं करते हैं, क्योंकि वर्डप्रेस को मैक्रोज़ के साथ एक्सेल किताबें पसंद नहीं हैं।
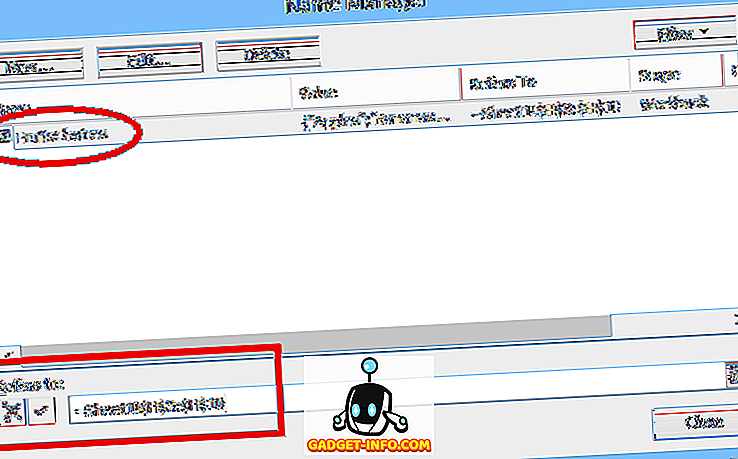
सूची ब्लॉक में पंक्तियों की संख्या निर्दिष्ट करने के विकल्प के रूप में, सूची ब्लॉक को अपना स्वयं का रेंज नाम सौंपा जा सकता है, जिसे तब संशोधित सूत्र में उपयोग किया जा सकता है। उदाहरण फ़ाइल में, एक दूसरी सूची (नाम) इस पद्धति का उपयोग करती है। यहां, संपूर्ण सूची खंड ("NAMES" शीर्षक के नीचे, उदाहरण फ़ाइल में 40 पंक्तियाँ) NameBlock का श्रेणी नाम दिया गया है । NamesList को परिभाषित करने का वैकल्पिक सूत्र तब है:
= OFFSET (नामकरण, 1, 0, IFERROR (MATCH (TRUE, INDEX) (ISBLANK ( NamesBlock ), 0, 0), 0) -1, ROWS (NamesBlock) ), 1)
जहां NamesBlock ने OFFSET (FruitHeading, 1, 0, 20, 1) और ROWS (NamesBlock) की जगह पहले के फॉर्मूले में 20 (पंक्तियों की संख्या ) को बदल दिया है।
तो, ड्रॉपडाउन सूचियों के लिए जिसे आसानी से संपादित किया जा सकता है (अन्य उपयोगकर्ताओं द्वारा जो अनुभवहीन हो सकते हैं सहित), गतिशील रेंज नामों का उपयोग करके देखें! और ध्यान दें कि, हालांकि इस लेख को ड्रॉपडाउन सूचियों पर केंद्रित किया गया है, लेकिन डायनामिक रेंज नामों का उपयोग कहीं भी किया जा सकता है, आपको एक सीमा या सूची का संदर्भ देने की आवश्यकता होती है जो आकार में भिन्न हो सकती है। का आनंद लें!