

जाहिर है, इंसानों की धारणा और कंप्यूटर जैसे इलेक्ट्रॉनिक उपकरण अलग-अलग होते हैं। मनुष्य प्राकृतिक भाषाओं के माध्यम से कुछ भी समझ सकता है, लेकिन एक कंप्यूटर नहीं करता है। कंप्यूटर को मानव पठनीय रूप में लिखी जाने वाली भाषाओं को कंप्यूटर पठनीय रूप में परिवर्तित करने के लिए अनुवादक की आवश्यकता होती है।
कंपाइलर और दुभाषिया भाषा अनुवादक के प्रकार हैं। भाषा अनुवादक क्या है? यह सवाल आपके मन में उठ रहा होगा।
एक भाषा अनुवादक एक सॉफ्टवेयर है, जो एक स्रोत भाषा से कार्यक्रमों का अनुवाद करता है जो मानव पठनीय रूप में एक वस्तु भाषा में एक समकक्ष कार्यक्रम में होते हैं। स्रोत भाषा आम तौर पर एक उच्च-स्तरीय प्रोग्रामिंग भाषा है, और ऑब्जेक्ट भाषा आमतौर पर एक वास्तविक कंप्यूटर की मशीन भाषा है।
तुलना चार्ट
| तुलना के लिए आधार | संकलक | दुभाषिया |
|---|---|---|
| इनपुट | यह एक समय में एक पूरा कार्यक्रम लेता है। | यह एक बार में कोड या निर्देश की एक पंक्ति लेता है। |
| उत्पादन | यह मध्यवर्ती वस्तु कोड उत्पन्न करता है। | यह किसी भी मध्यवर्ती वस्तु कोड का उत्पादन नहीं करता है। |
| काम करने का तंत्र | निष्पादन से पहले संकलन किया जाता है। | संकलन और निष्पादन एक साथ होता है। |
| गति | तुलनात्मक रूप से तेज | और धीमा |
| याद | ऑब्जेक्ट कोड के निर्माण के कारण मेमोरी की आवश्यकता अधिक होती है। | इसे कम मेमोरी की आवश्यकता होती है क्योंकि यह मध्यवर्ती ऑब्जेक्ट कोड नहीं बनाता है। |
| त्रुटियाँ | संकलन के बाद सभी त्रुटियों को प्रदर्शित करें, सभी एक ही समय में। | एक-एक करके प्रत्येक पंक्ति की त्रुटि प्रदर्शित करता है। |
| गलती पहचानना | कठिन | तुलनात्मक रूप से आसान |
| प्रोग्रामिंग भाषाओं से संबंधित | C, C ++, C #, Scala, टाइपस्क्रिप्ट कंपाइलर का उपयोग करता है। | जावा, पीएचपी, पर्ल, पायथन, रूबी एक दुभाषिया का उपयोग करता है। |
कंपाइलर की परिभाषा
एक कंपाइलर एक प्रोग्राम है जो उच्च-स्तरीय भाषा में लिखे गए प्रोग्राम को पढ़ता है और इसे मशीन या निम्न-स्तरीय भाषा में परिवर्तित करता है और प्रोग्राम में मौजूद त्रुटियों की रिपोर्ट करता है। यह पूरे स्रोत कोड को एक बार में कनवर्ट करता है या ऐसा करने के लिए कई पास ले सकता है, लेकिन अंत में, उपयोगकर्ता को संकलित कोड मिलता है जो निष्पादित करने के लिए तैयार है।

कंपाइलर चरणों पर संचालित होता है; विभिन्न चरणों को दो भागों में बांटा जा सकता है:
- कंपाइलर के विश्लेषण चरण को सामने के छोर के रूप में भी जाना जाता है जिसमें प्रोग्राम को मूलभूत घटक भागों में विभाजित किया जाता है और कोड के व्याकरण, अर्थ और वाक्यविन्यास की जांच करता है जिसके बाद मध्यवर्ती कोड उत्पन्न होता है। विश्लेषण चरण में लेक्सिकल विश्लेषक, सिमेंटिक विश्लेषक और वाक्यविन्यास विश्लेषक शामिल हैं।
- संकलक के संश्लेषण चरण को बैक एंड के रूप में भी जाना जाता है जिसमें मध्यवर्ती कोड को अनुकूलित किया जाता है, और लक्ष्य कोड उत्पन्न होता है। संश्लेषण चरण में कोड ऑप्टिमाइज़र और कोड जनरेटर शामिल हैं।
कम्पाइलर के PHASES
अब प्रत्येक चरण के काम को विस्तार से समझते हैं।
- लेक्सिकल एनालाइजर : यह कोड को पात्रों की एक धारा के रूप में स्कैन करता है, वर्णों के अनुक्रम को लेक्समेस में समूहित करता है और प्रोग्रामिंग भाषा के संदर्भ में टोकन के अनुक्रम को आउटपुट करता है।
- सिंटैक्स एनालाइज़र : इस चरण में, पिछले चरण में उत्पन्न होने वाले टोकन को प्रोग्रामिंग लैंग्वेज के व्याकरण के खिलाफ जांचा जाता है, कि भाव वाक्य-रचना सही हैं या नहीं। यह ऐसा करने के लिए पार्स ट्री बनाता है।
- सिमेंटिक एनालाइज़र : यह सत्यापित करता है कि पिछले चरण में उत्पन्न भाव और कथन प्रोग्रामिंग भाषा के नियम का पालन करते हैं या नहीं और यह एनोटेट पार्स ट्री बनाता है।
- मध्यवर्ती कोड जनरेटर : यह स्रोत कोड के समकक्ष मध्यवर्ती कोड उत्पन्न करता है। इंटरमीडिएट कोड के कई प्रतिनिधित्व हैं, लेकिन टीएसी (थ्री एड्रेस कोड) का सबसे अधिक उपयोग किया जाता है।
- कोड ऑप्टिमाइज़र : यह कार्यक्रम के समय और स्थान की आवश्यकता को बेहतर बनाता है। ऐसा करने के लिए, यह प्रोग्राम में मौजूद निरर्थक कोड को समाप्त कर देता है।
- कोड जनरेटर : यह कंपाइलर का अंतिम चरण होता है जिसमें किसी विशेष मशीन के लिए लक्ष्य कोड उत्पन्न होता है। यह मेमोरी प्रबंधन, रजिस्टर असाइनमेंट और मशीन विशिष्ट अनुकूलन जैसे संचालन करता है।
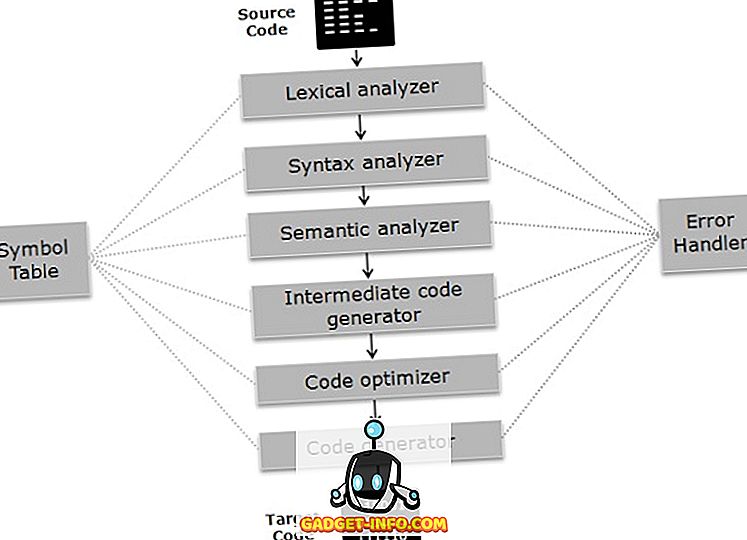
प्रतीक तालिका कुछ हद तक एक डेटा संरचना है जो पहचानकर्ताओं को उस संबंधित प्रकार के डेटा के साथ प्रबंधित करती है जो इसे संग्रहीत कर रहा है। त्रुटि हैंडलर एक कंपाइलर के विभिन्न चरणों के बीच में त्रुटियों का पता लगाता है, रिपोर्ट करता है, सही करता है।
इंटरप्रेटर की परिभाषा
दुभाषिया एक प्रोग्रामिंग भाषा को लागू करने के लिए एक विकल्प है और एक संकलक के रूप में एक ही काम करता है। दुभाषिया एक कंपाइलर के समान लेक्सिंग, पार्सिंग और टाइप चेकिंग करता है। लेकिन दुभाषिया वाक्यविन्यास पेड़ से सीधे कोड का उपयोग करता है और वाक्यविन्यास वृक्ष से कोड उत्पन्न करने के बजाय कथन को निष्पादित करता है।
एक दुभाषिया को एक ही वाक्यविन्यास वृक्ष को एक से अधिक बार संसाधित करने की आवश्यकता हो सकती है यही कारण है कि व्याख्या अनिवार्य रूप से संकलन कार्यक्रम को निष्पादित करने की तुलना में धीमी है।
संकलन और व्याख्या शायद एक प्रोग्रामिंग भाषा को लागू करने के लिए संयुक्त है। जिसमें एक कंपाइलर इंटरमीडिएट-लेवल कोड जनरेट करता है तो कोड को मशीन कोड के बजाय संकलित किया जाता है।
कार्यक्रम के विकास के दौरान दुभाषिया का इस्तेमाल करना फायदेमंद होता है, जहां सबसे महत्वपूर्ण हिस्सा कार्यक्रम को कुशलता से चलाने के बजाय तेजी से एक कार्यक्रम संशोधन का परीक्षण करने में सक्षम होना है।
संकलक और दुभाषिया के बीच महत्वपूर्ण अंतर
आइए Compiler और Interpreter के बीच के प्रमुख अंतरों को देखें।
- कंपाइलर एक प्रोग्राम को पूरी तरह से लेता है और उसका अनुवाद करता है, लेकिन दुभाषिया प्रोग्राम स्टेटमेंट को स्टेटमेंट द्वारा ट्रांसलेट करता है।
- संकलक के मामले में मध्यवर्ती कोड या लक्ष्य कोड उत्पन्न होता है। दुभाषिया के खिलाफ के रूप में मध्यवर्ती कोड नहीं बनाता है।
- एक कंपाइलर तुलनात्मक रूप से इंटरप्रेटर से अधिक तेज है क्योंकि कंपाइलर एक बार में पूरे कार्यक्रम को ले जाता है जबकि दुभाषिए एक के बाद एक कोड की प्रत्येक पंक्ति को संकलित करते हैं।
- कंपाइलर को ऑब्जेक्ट कोड की पीढ़ी के कारण दुभाषिया की तुलना में अधिक मेमोरी की आवश्यकता होती है।
- कंपाइलर सभी त्रुटियों को समवर्ती रूप से प्रस्तुत करता है, और एक-एक करके प्रत्येक स्टेटमेंट की कंट्रास्ट इंटरप्रेटर डिस्प्ले की त्रुटियों का पता लगाना मुश्किल होता है, और त्रुटियों का पता लगाना आसान होता है।
- कंपाइलर में जब प्रोग्राम में कोई त्रुटि होती है, तो वह इसका अनुवाद रोक देता है और त्रुटि को हटाने के बाद पूरे प्रोग्राम को फिर से अनुवादित किया जाता है। इसके विपरीत, जब दुभाषिया में कोई त्रुटि होती है, तो यह इसके अनुवाद को रोकता है और त्रुटि को हटाने के बाद, अनुवाद फिर से शुरू होता है।
- एक संकलक में, प्रक्रिया को दो चरणों की आवश्यकता होती है जिसमें सबसे पहले स्रोत कोड को लक्षित कार्यक्रम के लिए अनुवाद किया जाता है फिर निष्पादित किया जाता है। जबकि दुभाषिया में यह एक चरण की प्रक्रिया है जिसमें एक ही समय में सोर्स कोड संकलित और निष्पादित किया जाता है।
- संकलक का उपयोग प्रोग्रामिंग भाषाओं जैसे C, C ++, C #, Scala, आदि में किया जाता है। अन्य दुभाषिया पर जावा, PHP, रूबी, पायथन, आदि भाषाओं में नियोजित किया जाता है।
निष्कर्ष
कंपाइलर और दुभाषिया दोनों को एक ही काम करने का इरादा है, लेकिन ऑपरेटिंग प्रक्रिया में भिन्नता है, कंपाइलर एक समग्र तरीके से स्रोत कोड लेता है जबकि दुभाषिया स्रोत कोड के घटक भागों को लेता है, अर्थात, बयान द्वारा बयान।
यद्यपि संकलक और दुभाषिया दोनों के कुछ फायदे और नुकसान हैं, जैसे व्याख्या की गई भाषाओं को क्रॉस-प्लेटफॉर्म के रूप में माना जाता है, अर्थात, कोड पोर्टेबल है। यह संकलक के विपरीत पहले से निर्देश संकलित करने की आवश्यकता नहीं है जो समय की बचत है। संकलित प्रक्रिया के संबंध में संकलित भाषाएं तेज हैं।